CUDA grid
-
2 level hierarchy: blocks, threads
-
Idea: map threads to multi-dimensional data
-
All threads in a grid execute the same kernel
-
Threads in same block can access the same shared memory
-
Max block size: 1024 threads
-
built-in 3D coordinates of a thread:
blockIdx, threadIdx- identify which portion of the data to process -
shape of grid & blocks:
gridDim: number of blocks in the grid (not so often used)blockDim: number of threads in a block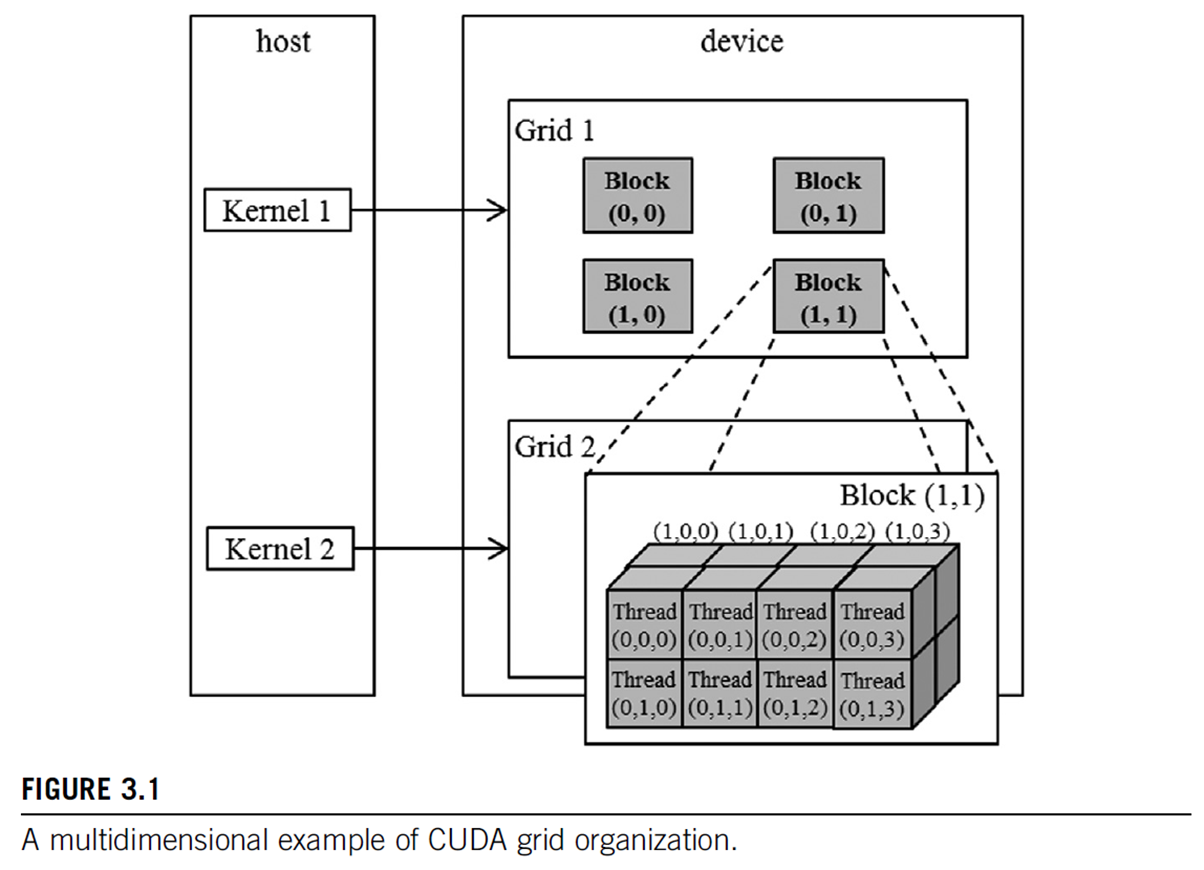
Grid shape
- How to define
blockDimis dependent on cache - The grid can be different for each kernel launch, e.g., dependent on data shapes
- Threads can be scheduled in any order
- You can use fewer than 3dims (set others to 1)
- e.g. 1D for sequences
dim3 grid(32,1,1,);
dim3 block(128,1,1);
kernelFunction<<grid, block>>>(...);
// Number of threads: 128 * 32 = 4096nd-Arrays in Memory
-
Logical view of the data
-
Row-major layout in memory
-
2D array can be linearized in two ways:
- row-major (contiguous elements form rows)
- column-major (contiguous elements form columns)
- important for how to think about data accesses in your code and how cache-friendly they are
- indexing a whole row is cache-friendly if row-major layout.
-
Torch tensors & numpy ndarrays use strides to specify how elements are laid out in memory
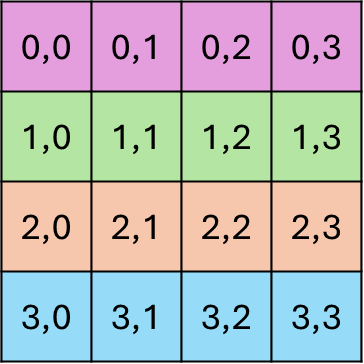
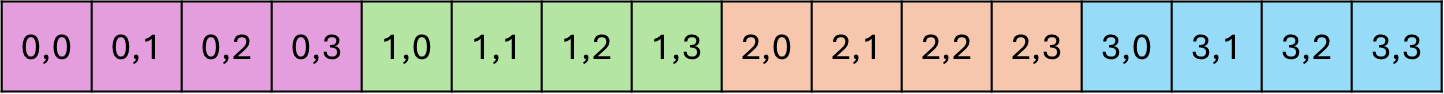
Image blur example (3.3, p.60)
- Mean filter example blurKernel
- shows row-major pixel memory access (in & out pointers)
- nice showcase of 3D data access
Interesting snippets
- Defining the threads and blocks
// helper function for ceiling unsigned integer division
inline unsigned int cdiv(unsigned int a, unsigned int b) {
return (a + b - 1) / b;
}
dim3 threads_per_block(16, 16, channels);
dim3 number_of_blocks(
cdiv(width, threads_per_block.x),
cdiv(height, threads_per_block.y)
);
mean_filter_kernel<<<number_of_blocks, threads_per_block, 0, torch::cuda::getCurrentCUDAStream()>>>(
result.data_ptr<unsigned char>(),
image.data_ptr<unsigned char>(),
width,
height,
radius
);- Getting current row, col, and channel
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int channel = threadIdx.z;
int baseOffset = channel * height * width;- Row-major access
for (int blurRow=-radius; blurRow <= radius; blurRow += 1) {
for (int blurCol=-radius; blurCol <= radius; blurCol += 1) {
int curRow = row + blurRow;
int curCol = col + blurCol;
if (curRow >= 0 && curRow < height && curCol >=0 && curCol < width) {
pixVal += input[baseOffset + curRow * width + curCol];
pixels += 1;
}
}
}