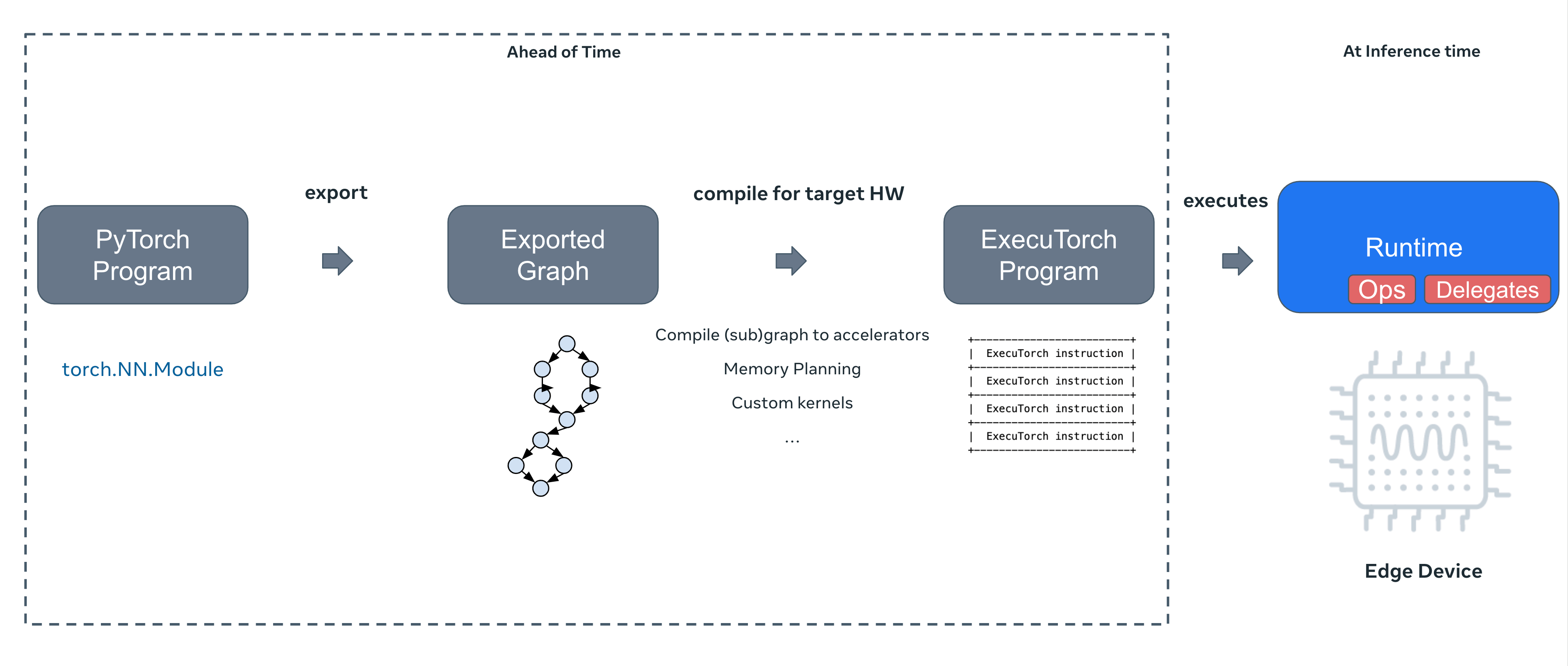
High-level (export, transformation, and compilation)
-
Export the model
- capture the pytorch program as a graph
-
Compile the exported model to an ExecuTorch program
- Given an exported model from step 1, convert it to an executable format called an ExecuTorch program that the runtime can use for inference.
- entry point for various optimizations
- quantization
- further compiling subgraphs down to on-device specialized hardware accelerators to improve latency.
- memory planning, i.e. plan the location of intermediate tensors to reducememory footprint.
-
Run the ExecuTorch program on a target device.
- input → output (nothing eager, execution plan already calculated in step 1 and 2)
-
Architectural Components
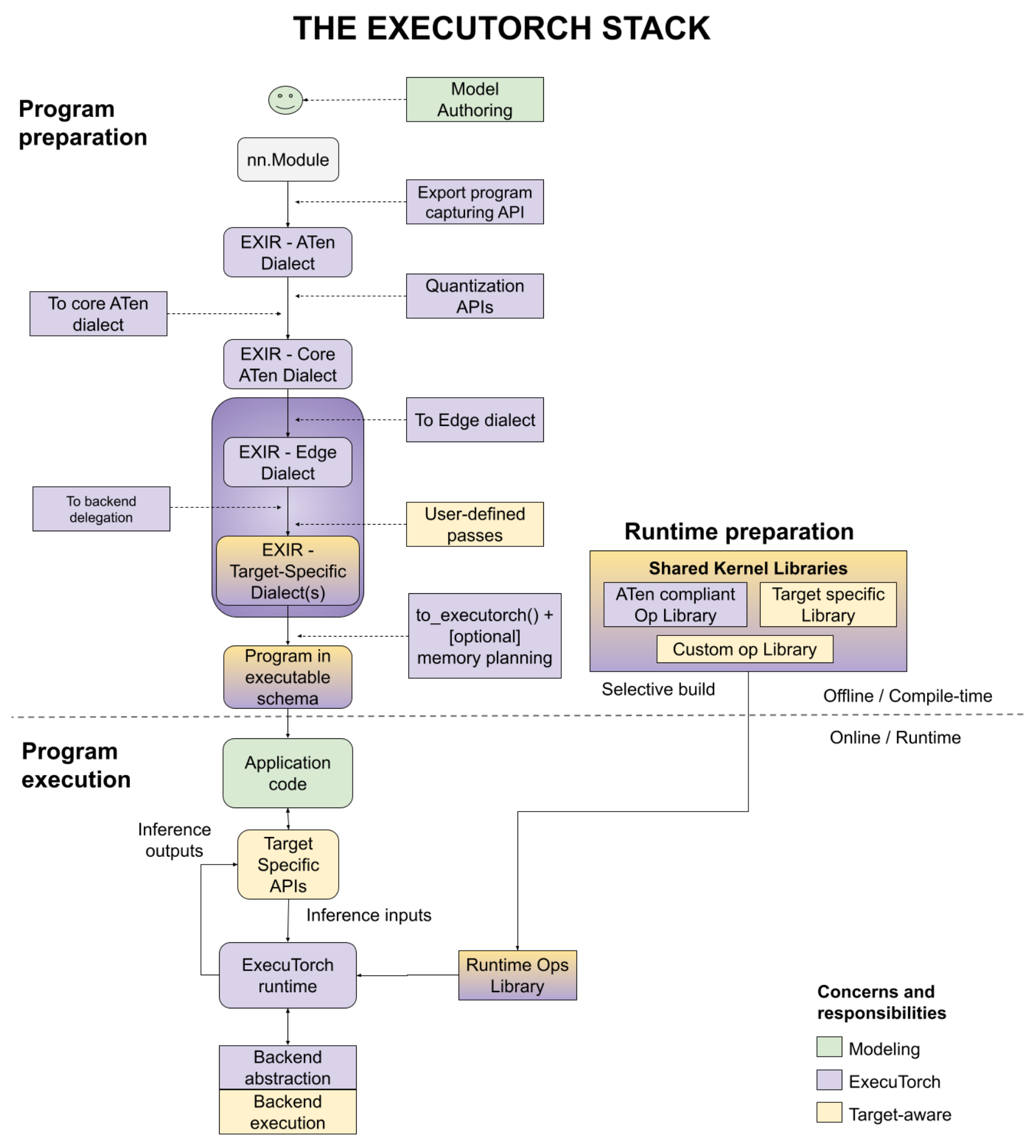
Program preparation
-
leverage pytorch 2 compiler to do AOT (ahead-of-time) torch.export()
-
compile to edge dialect + compile to executorch program Edge Compilation
End-to-end workflow
import torch
from torch.export import export, export_for_training, ExportedProgram
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
example_args = (torch.randn(3, 4),)
pre_autograd_aten_dialect = export_for_training(M(), example_args).module()
# Optionally do quantization:
# pre_autograd_aten_dialect = convert_pt2e(prepare_pt2e(pre_autograd_aten_dialect, CustomBackendQuantizer))
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: exir.EdgeProgramManager = exir.to_edge(aten_dialect)
# Optionally do delegation:
# edge_program = edge_program.to_backend(CustomBackendPartitioner)
executorch_program: exir.ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
)
)
with open("model.pte", "wb") as file:
file.write(executorch_program.buffer)