Goal: A single, simple architecture for all modalities
-
Why?
- We’re hoping for the bitter lesson to kick in, and that have a full end-to-end solution will allow us to have cross-modal synergies
-
We have scaling laws, explained in Scaling Laws For Generative Mixed-Modal Language Models
Chameleon
- Everything is a token, one large AR transformer
- ~1k tokens for images
- For generation, we always generate the 1k tokens for the images in raster-order
- Given this is fixed-length, we can probably do better by switching images to diffusion.
- Can also use things like FlexTok for adaptive number of tokens. Generate in a coarse-to-fine manner.
Training instabilities
-
Training instabilities have been observed when training a large multimodal “monolithic” model
- In Chameleon, they report that the cause of the divergence is due to the softmax operation being problematic when training with multiple modalities of significantly varying entropy, due to the translation invariant property of softmax (i.e., softmax(z) = softmax(z + c)).
- Because they share all weights of the model across modalities, each modality will try to “compete” with the other by increasing its norms slightly
-
Mitigations i.e. controlling norm growth:
- For the 7B:
- QK-Norm (controls the norm growth of the attention logits)
- layer-norm the query and keys before doing the dot product
- z-loss (controls for the divergence in the output logits)
- Let denote the model’s output logits, which are used to compute class probabilities via a softmax where .
- They add an auxiliary loss , referred to as z-loss, with a coefficient of , to encourage to stay close to 1.
- Lower LR
- QK-Norm (controls the norm growth of the attention logits)
- For the 7B:
-
For the 34B, they had even more instabilities:
- Paying close attention to unusually large values in your forward pass
- paying attention to the placement of layer norms, they used Swin-Norm
- In Chameleon, they use layer-norm after the self-attention & MLP, instead of before
- It bounds the norm of what’s added to the residual stream.
-
Switching images to diffusion is a fix
Tokenizer
- VQ-VAE image tokenizer introduces irreversible information loss, hurting image understanding and generation.
- There’s some irreducible loss, and this gap grows bigger as we scale the models, compared to a continuous model
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Architecture 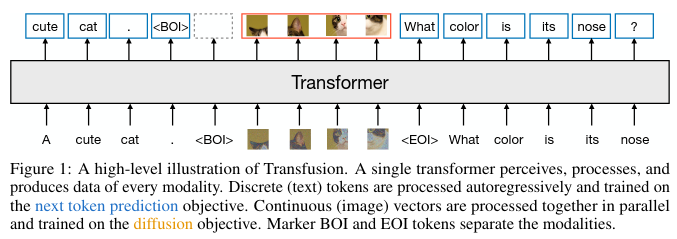
-
Input is text (that gets tokenized), and image (that gets split into patches, and projected into continuous space). Around 64 patches per image.
-
Using continuous embeddings allows for much higher quality, and easier learning
-
They use latent diffusion.
-
We can use modality-specific encoding-decoding
-
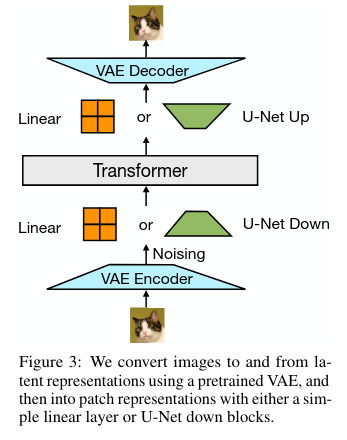
Comparing Transfusion and Chameleon
-
Same data, compute and architecture
- Train VQ-VAE and VAE with same data and compute
- Linear encoding for images
-
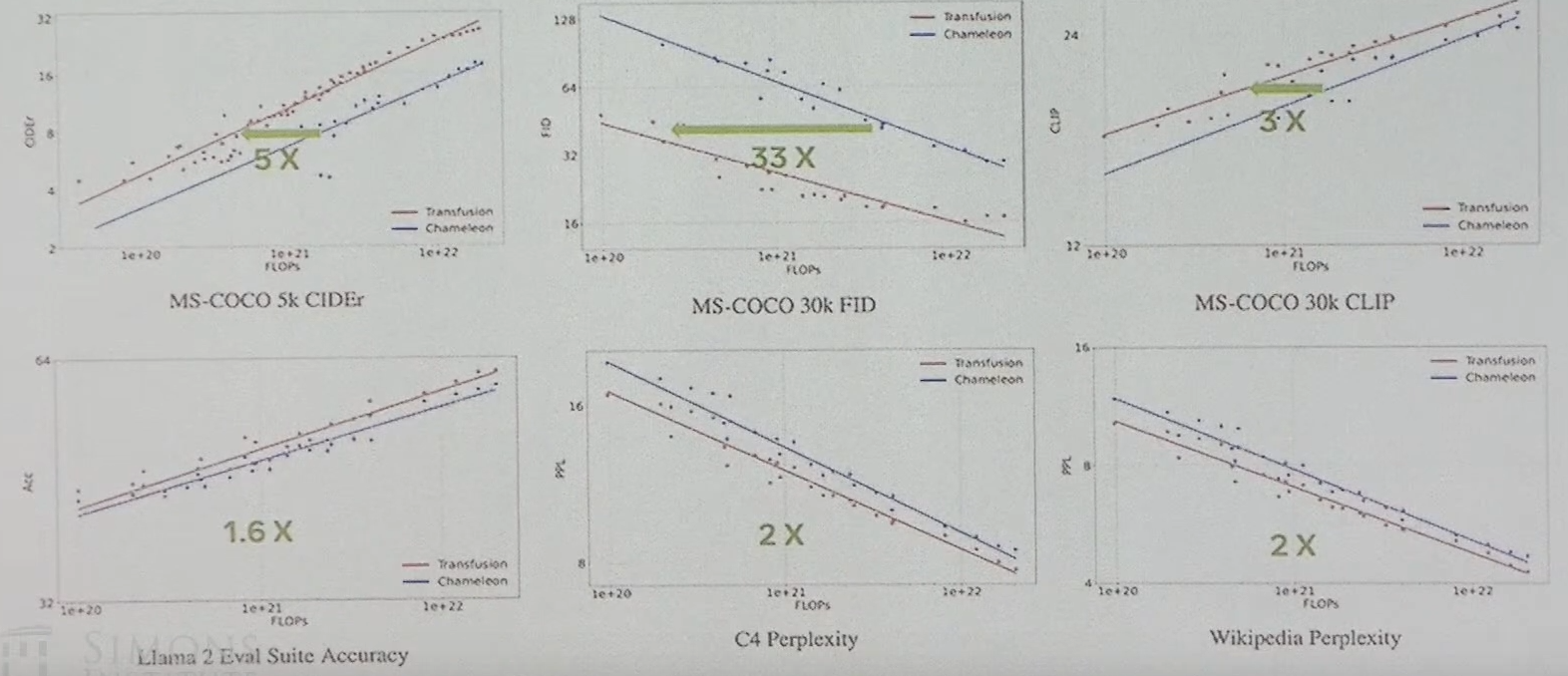
Transfusion scales significantly better than Chameleon
-
Why?
- Most stability issues went away
- One hypothesis is that this stems from the competition between text and image tokens in the output distribution; alternatively,
- it is possible that diffusion is more efficient at image generation and requires fewer parameters, allowing Transfusion models to use more capacity than Chameleon to model text
- No irrecoverable loss from discrete tokenization
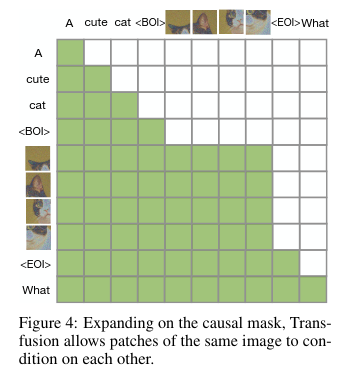
Inference
- Inference uses mode-switching.
- Normal AR for text
- When we see beginning of image token, we switch to diffusion, and sample for steps.
- Note that the attention layers are still attending to the full history, even during diffusion.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
-
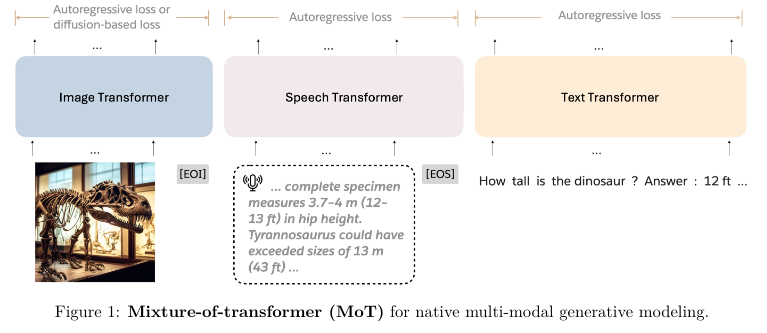
-
Each modality has its own transformer
-
Determine routing based on modality
-
Self-attention spans transformers
-
Joint end-to-end training
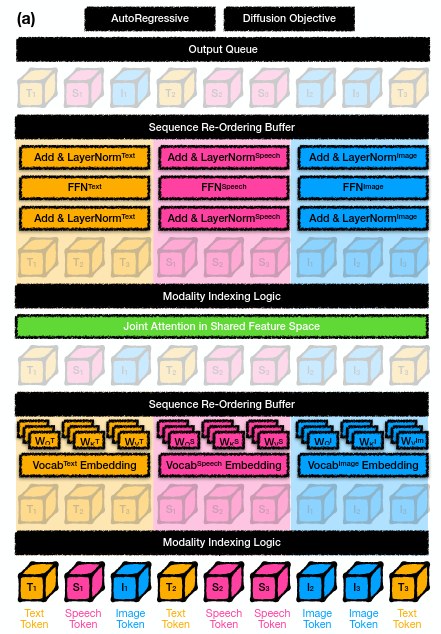
What does a layer look like ?
- Channel-mixing layers (e.g. FFNs) process only their own modality
- The sequence-mixing layers (self-attention) maintain the global order and computes over the whole sequence.
How does it scale compared to dense and MoE
- The analysis revealed that MoT consistently required only 45.5% of the dense model’s training steps to achieve comparable pre-training loss, indicating a substantial and sustained acceleration throughout training.
- Modality-specific analysis showed MoT’s particular effectiveness in the image modality, requiring only 34.8% of the dense model’s training steps to match final loss (Figure 5c-f). MoE-4x showed limited improvement in this domain.
- For text, both MoT and MoE-4x outperformed the dense model, with MoT showing comparable or slightly better gains.
Hetereogeneous scaling of the parameters
- One limitation is that in the current framing, the different modality components need to be of the same size. At least for the self-attention.
- We’d like to scale image-1x and text-4x.
- LLMs get better and better with scale
- Image diffusion models not so much, they seem to saturate at 10B
- What they do is that they use an MoE-4x for the text FFNs.
- This help a lot with the text performance.