-
EoRA: Training-free Compensation for Compressed LLM with Eigenspace Low-Rank Approximation
-
It’s a plug-in LoRA-style adapter that reconstructs the errors introduced by compression (especially 3- / 4-bit GPTQ) without any gradient-based fine-tuning
-
Main idea is:
- Compressed model + small calibration set → project the compression error into the activation eigenspace → fit a low-rank adapter where large eigen-values get priority.

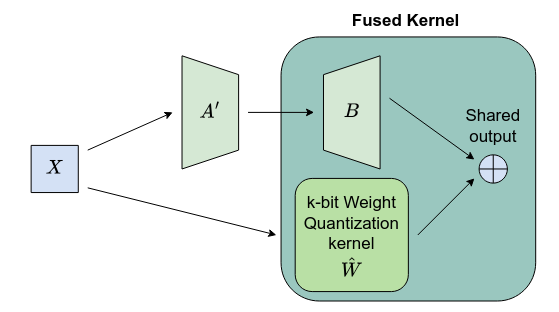
- Without fusion, this scheme leads to a noticeable increase in latency. This is primarily because input and output must transfer between L2 cache and DRAM twice as often compared to that without a low-rank residual path, shifting the inference process from being computation-bound to memory-bound.
This is how they fuse it into the quantized linear