General architecture components
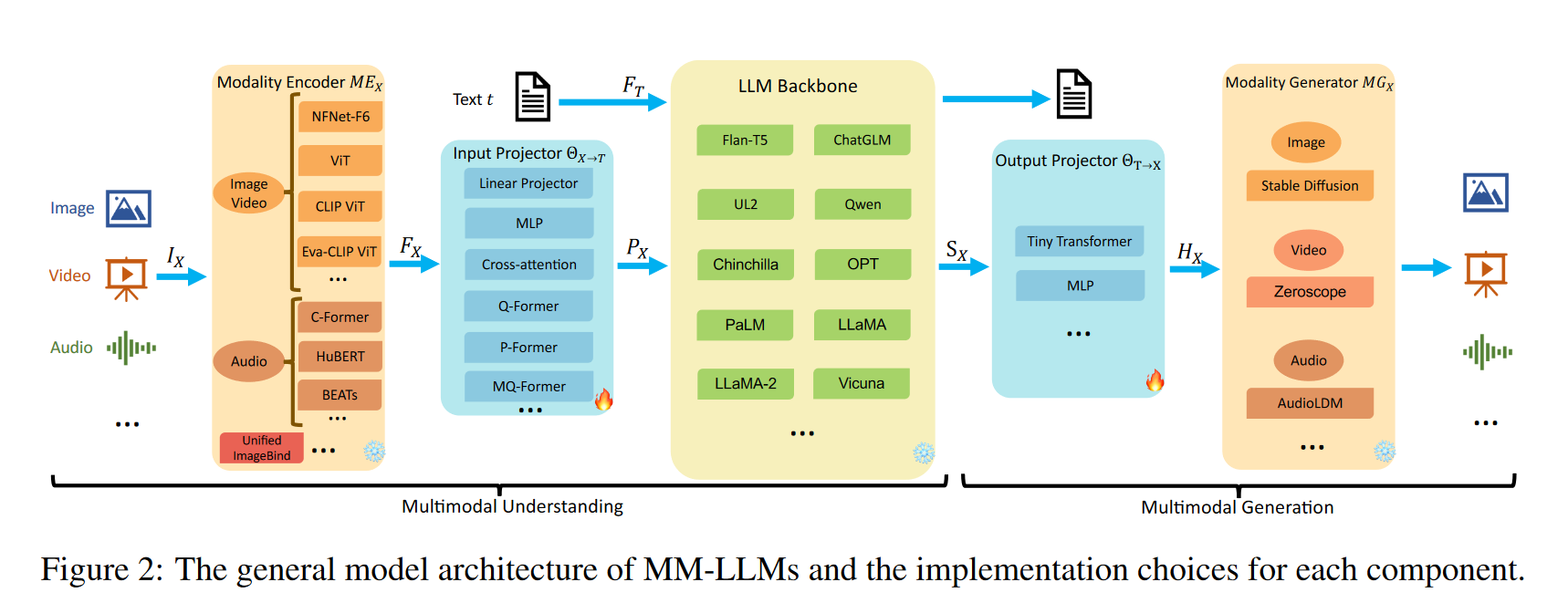
- During training,
- Modality Encoder, LLM Backbone, and Modality Generator are generally maintained in a frozen state.
- The primary optimization emphasis is on Input and Output Projectors.
- Given that Projectors are lightweight components, the proportion of trainable parameters in MM-LLMs is notably small compared to the total parameter count (typically around 2%).
Modality Encoder
-
, we want to extract features
-
Vision: CLIP, SigLip
-
Audio: Whisper, CLAP
-
ImageBind: joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data.
- allows for multimodal-conditioned generation
- aligns each modality’s embeddings to the image embeddings (potentially extracted from CLIP)
- no explicitly aligned pseudo-labeled dataset

Input Projector
- The Input Projector is tasked with aligning the encoded features of other modalities with the text feature space . The aligned features as prompts are then fed into the LLM Backbone alongside the textual features .
- Given -text dataset , the goal is to minimize the -conditioned text generation loss
- If we’re also generating the modality i.e. , the the loss becomes
LLM backbone
- It produces (1) direct textual outputs t, and (2) signal tokens from other modalities (if any).
- These signal tokens act as instructions to guide the generator on whether to produce MM contents
Output Projector
- The Output Projector maps the signal token representations from the LLM Backbone into features understandable to the following Modality Generator .
- Given -text dataset , is first fed into LLM to generate the corresponding , then mapped into
- To facilitate alignment of the mapped features , the goal is to minimize the distance between and the conditional text representations of :
- is the textual condition encoder in
- To facilitate alignment of the mapped features , the goal is to minimize the distance between and the conditional text representations of :
Modality Decoder/Generator
- The Modality Generator is tasked with producing outputs in distinct modalities.
- Need to able to parse LLM response if the response is text only i.e. H_X is the identity
- Common:
- Stable Diffusion (image)
- Zeroscope, Videofusion (video)
- AudioLDM-2 (audio)
- Can also compute text-conditioned noise-matching loss to tune the input and output projectors
Review of existing architectures
I will review LlaVA, ModaVerse,Chameleonas they cover relevant different approaches to multi-modality.
LlaVA
- The two modalities are image and text.
- The use case for LLaVA is general purpose visual+language understanding e.g. given an image, the model should be able to answer a question on the content of the image.
- The model doesn’t have the ability to generate images.
Components
- Text Tokenizer
- Large Language Model (the “knowledge processing unit”, Vicuna)
- Vision encoder (CLIP) + Input projector (MLP)
- The image is encoded using CLIP, which gives us tokens, which are then projected to the expected embedding size of the LLMs, and also aligned with the LLM text embedding space
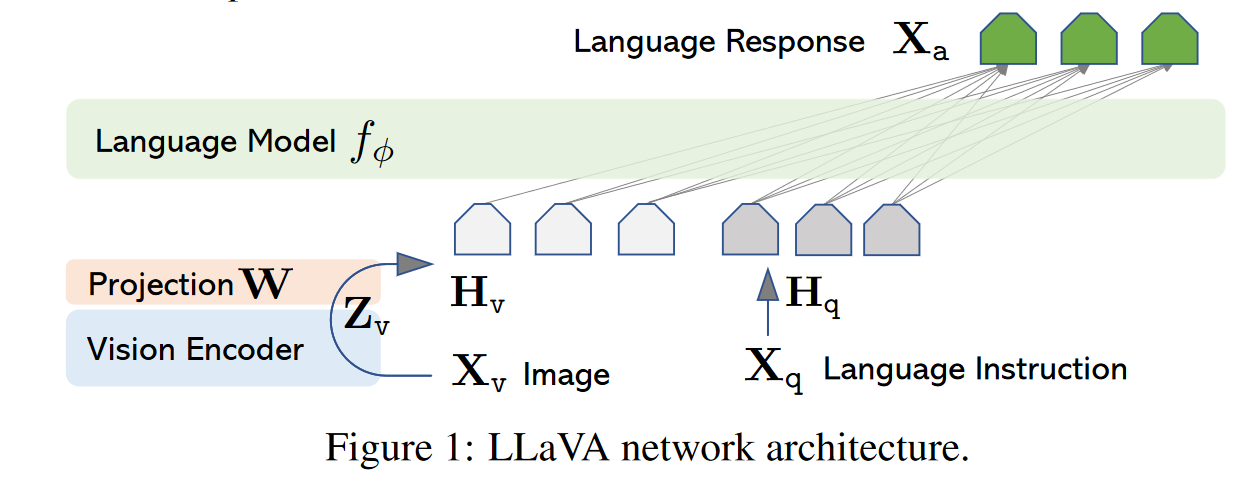
Integration strategy
- They use instruction following data..
- They convert image-text pairs into instruct-following pairs, by providing GPT-4 with captions + other contexts (e.g. bounding boxes) to generate questions and answers (following 3 types: conversation style, detailed description, complex reasoning) and get , where is the question/instruction, is the visual content, and is the answer.
- They also create multi-turn conversation data, where the beginning turn is the visual content + some instruction, and all the next turns are just additional questions
- They then align/train the MLP Input Projector + LLM
- by computing the usual auto-regressive training objective, i.e. next-token predicition/cross-entropy between the true answer and the prediction of the LLM, given image and text input,
- The vision encoder is frozen.
ModaVerse
- There are 4 modalities: text, image, video and sound
- The use-case for ModaVerse is comprehending and transforming content across various modalities including images, videos, and audio, i.e. understanding + generation (slight emphasis on generation though).
Components
- Text tokenizer
- Large Language Model (the “knowledge processing unit”, Vicuna)
- ImageBind encoder (takes in image, video, and audio modalities)
- One input projector per modality, except for text.
- Three text-conditioned generators (text-to-image, text-to-video, text-to-audio)
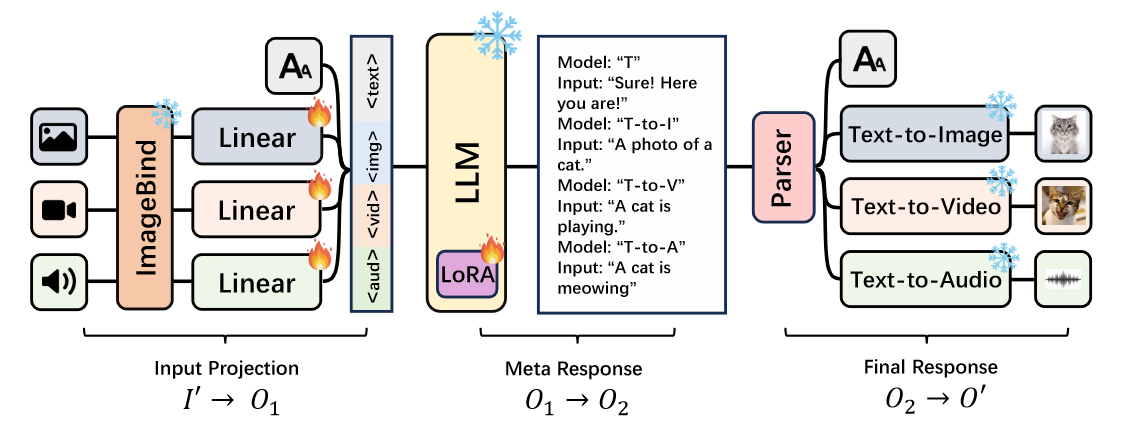
Integration strategy
- The foundational LLM can only output text ⇒ they address this limitation by treating the foundational LLM as an agent, designed to produce meta-responses (when prompted to generate data).
- The meta-response comprises formatted information that includes the invocation details for a specific text-to-modality generator
- They employ an instruction-following training approach.
-
For general multi-modal understanding, they use datasets from previous works e.g. LLaVA, VideoChat, …
-
For training the LLM to generate meta-responses, they need a dataset consisting of
- where is the text-instruction, e.g., “Generate an image of an animal based on this audio clip of its vocalization”
- is the conditioning modality, e.g., audio input of a cat
- is the corresponding response that the LLM should generate, e.g., in our running example, it’s the meta-response {Model: “T-to-I”, Input: “A photo of a cat”}.
-
They leverage the training datasets of the generative models
- The datasets of generative models typically provide both non-textual data, such as images, videos, or audio, and their corresponding textual descriptions (in the format that the generative models expects)
- Similar to LLaVA, they use GPT-4 to generate both and .
-
Chameleon
- The two modalities are image and text.
- Goal: understanding and generating images and text in any arbitrary sequence
Components
- Text Tokenizer
- Image Tokenizer
- 1 large multi-modal model trained from scratch
Integration strategy
- Using tokenizers for both modalities allows to apply the same transformer architecture to sequences of both image and text tokens.
- You can just use the next-token prediction objective to train both modalities.
- The dataset can consist of text-only, text/image pairs, or full interleaved text-image documents.
- Pretraining stage (80% of compute)
- Text-only: 2.9T tokens (similar to Llama2 and CodeLLaMa)
- Text-image: 1.5T tokens (no clear details)
- Text-image interleaved: 400B tokens (Obelisc dataset)
- Pretraining stage (80% of compute)
Strengths, weaknesses, ease of implementation
Ease of implementation
- LLaVA:
- very easy to implement, no additional logic from classic LLM, just append the image tokens to the text tokens.
- ModaVerse:
- moderately easy to implement, input logic is the same as LlaVA.
- Some additional logic needs to be implemented to correctly parse the meta-responses from the LLM and feeding them to the text-to-modality generators
- Chameleon:
- quite hard to implement
- Training from scratch involves all the complexities of large-scale distributed training.
- The data processing is not entirely trivial to implement, especially dealing with interleaved-text documents, you need good data classes definition.
- There are challenges related to the optimization stability of such large monolithic multi-modal model
- Using tokenizers for each modality also brings complexity:
- You need to train them, choose a correct codebook size, need to decide the “patch size” which decides the sequence length of your modality. There are tradeoffs between how succinct the representation is, and how accurately it can describe the information content.
- This means you’re bottlenecked by how good your tokenizer is
- In chameleon, the core weakness of their tokenizer is in reconstructing images with a large amount of text, therefore upper bounding the capability of the model, when it comes to heavy OCR-related tasks.
- There’s also complexities with respect to handling generation. More discussion later.
Compute
- LLaVA: (moderate compute)
- uses pretrained LLM
- trains the input projector + finetunes the LLM
- ModaVerse: (low compute)
- uses pretrained LLM
- trains the input projectors + LoRA of the LLM.
- Chameleon: (very high compute)
- Mixed-model from inception and uses a uniform architecture trained from scratch in an end-to-end fashion on an interleaved mixture of all modalities
Flexibility
-
Both LLaVA and ModaVerse could technically support interleaved text-image inputs or multiple image inputs, by having beginning and end of modality tokens, but I don’t think they do.
-
LLaVA:
- a little bit flexible
- doesn’t support interleaved text-image output
- can only generate text
- can potentially add new modalities by just adding new input projectors.
-
ModaVerse:
- a little bit flexible
- can generate multiple modalities
- could potentially support interleaved text-image output by interleaving meta-responses and normal text, but you’d need fairly complex logic to parse the meta-response mid-stream, generate them, and adding them back to the context.
- You need a dedicated text-to-modality generator for each new modality.
-
Chameleon:
- very flexible
- supports interleaved text-image input and output
- can add any modality as long you can tokenize it.
Performance
- In terms of compute, all methods’ inference compute increases with the number of modalities inputted, where the increase in compute comes from the increase in sequence length. In terms of model sizes, the main model (LLM or MMLM) all have approximately similar parameter sizes (7B-34B).
Understanding
-
LlaVA:
- pretty good at understanding
- however its understanding capabilities may be bottlenecked by the fact that the image modality is only added post pretraining,
- Indeed, the “knowledge extraction” part is done by CLIP, which wasn’t trained on the same data and with the same objective as the LLM, which most likely leads to a misalignment between the “semantics” (~relevant features to understand the “world”) extracted by CLIP and the “semantics” of the LLM.
- note: the paper “The Platonic Representation Hypothesis” suggests that “Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces.”. Thus, the misalignment might not be very large. (but I haven’t had time to read the paper, I just skimmed it)
- and thus the input projector mostly learns to align the image features “semantics” to the text feature “semantics”, so that the LLM is able to reason over them
- pretty good at understanding
-
ModaVerse:
- mainly focuses on generation
- has some understanding capabilities, because part of its instruction following dataset was about reasoning.
-
Chameleon:
- The early-fusion approach, where all modalities are projected into a shared representational space from the start (and trained end-to-end), allows for seamless knowledge transition between different modalities, and allows for “synergies” between modalities, i.e., a model trained on text+image might outperform a text-only model on a text-only task.
Generation
- LLaVA:
- cannot generate other data than text
- ModaVerse:
- can generate other data but its consistency (e.g. ) is not great because the generative models are not involved in the training loop. The models are only prompted through text.
- As a result, text may not be precise enough to accurately guide the generation process, compared to generating directly the input text features that the generative model uses as conditioning (i.e. soft prompt vs hard prompt).

- Even in the case where we can output “soft prompts”, to support direct editing of an image like the example above, because generator and LLM don’t have a shared space, (assuming they’re using a T2i diffusion model), they would need to detect an “edit” command in the meta-response, and use DDIM-inversion or SDEdit with the inputted modality to “mimic” having a shared feature space between the T2i model and the LLM.
- Chameleon:
- can natively generate other modalities, simply by predicting token sequences, and subsequently de-tokenizing them.
- very high consistency between input and output, as all the processing is done in the shared feature space.
- (the text below copied from Chameleon paper, given they explain it quite well) Autoregressive, mixed-modal generation introduces unique performance-related challenges at inference time.
- Data-dependencies per-step, given that the decoding formulation changes depending on whether the model is generating images or text at a particular step, tokens must be inspected at each step (i.e. copied from the GPU to the CPU in a blocking fashion) to guide control flow.
- Masking for modality-constrained generation — to facilitate exclusive generation for a particular modality (e.g. image-only generation), tokens that do not fall in a particular modality space must be masked and ignored when de-tokenizing.
- Fixed-sized units — unlike text-only generation, which is inherently variable-length, token-based image generation produces fixed-size blocks of tokens corresponding to an image.